 .
.
Vragenlijsten bestaan uit verschillende onderdelen die alle uit tekst
bestaan: uitleg, vragen, antwoorden, scoringssleutels, normen, regels voor
rapportgenereren en rapportteksten. In CDLJava staan deze gegevens in een
lijstbestand die met elke tekstverwerker of editor bijvoorbeeld Notepad
gemaakt kan worden. Voor een rapportgenerator zijn er nog bestanden met
stukjes tekst die bij rapportgenereren op basis van een scorerange gekozen
kunnen worden. Alle bestanden zijn zogenaamde ASCI-bestanden en geen
tekstverwerkerbestanden.
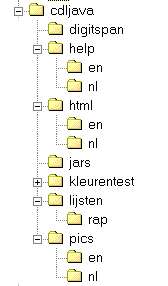
Deze bestanden moeten op de juiste plaats staan wil CDLJava ermee kunnen
werken. CDLJava staat standaard in de map "cdljava"; waar deze map staat is niet
van belang (vaak op c:\). Deze map bevat andere mappen zoals: "cdljava\lijsten","cdljava\lijsten\rap","pics"
en "jars". In "pics" staan plaatjes voor CDLJava en HTML pagina's en in
de map "jars" staan classes (programma code voor CDLJava en andere programma's
zoals doolhoven, fingertapping en kleurentest). De map "Html" bevat de handleiding
terwijl in de map 'help" helpteksten staan.
 In de map
"cdljava\lijsten" zitten de vragenlijsten; voor elke vragenlijst een tekstbestand.
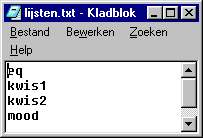
Tevens bevat deze map het bestand "lijsten.txt", hierin staan de vragenlijsten
die in CDLJava in een browser te kiezen zijn; CDLJavapro maakt hier geen gebruik van.
In de map
"cdljava\lijsten" zitten de vragenlijsten; voor elke vragenlijst een tekstbestand.
Tevens bevat deze map het bestand "lijsten.txt", hierin staan de vragenlijsten
die in CDLJava in een browser te kiezen zijn; CDLJavapro maakt hier geen gebruik van.
Een vragenlijst toevoegen aan CDLJava betekent

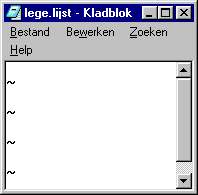 Een lege lijst bestaat uit minimaal vier tildes.
Een lege lijst bestaat uit minimaal vier tildes.
In het eerste veld komt de uitleg en instructie.
Dit is een simpele tekst die bij voorkeur op één scherm past. Zie voor
een voorbeeld De lijst EQ.
In het tweede veld komen de antwoorden
en vragen. Dit veld bestaat uit meerdere subvelden die gescheiden worden
met een hekje (#):
Raven met plaatjesMen kan voor de antwoorden per vraag een actuele set van antwoorden meegeven door na de vraagtekst een regel op te nemen met $keuzen gevolgd door de antwoordcategorieën. Het aantal gebruikte antwoorden mag nooit het oorspronkelijke aantal aan het begin overschrijden, minder mag wel. Bijvoorbeeld:
Deze test bevat plaatjes en drie keuze antwoorden
#
3
1.
2.
3.
#1
$picture: lijsten/pics/raven1.jpg
#2
$picture: lijsten/pics/raven2.jpg
#
DAT analogieënEen vragenlijst kan ook niet-lineair worden afgenomen. Afhankelijk van het antwoord kunnen bepaalde vragen wel of juist niet worden afgenomen. Op deze manier kan een vragenlijst specifieke routes bevatten, bijvoorbeeld afhankelijk van het geslacht, de burgerlijke staat e.d..
#
5
1.
2.
3.
4.
5.
#1
1 ... staat tot boek als beeldhouwer staat tot ...
$keuzen
1 dichter - kunstenaar
2 schrijver - beeld
3 letters - beitel
4 lezer - marmer
5 papier - steen
#2.
2 ... staat tot kroon als rechter staat tot ...
$keuzen
1 troon - advocaat
2 zilver - recht
3 getuige - wet
4 koning - toga
5 waardigheid - strengheid
test route
#
4
1 geheel niet
2 een beetje
3 tamelijk veel
4 zeer veel
#1
$goto 2 3 1 1 1
Ik ben een
$keuzen
1. man
2. vrouw
#2
$goto 4 4 4 4 4
In welke mate bent u blij een man te zijn?
$keuzen
1 geheel niet
2 een beetje
3 tamelijk veel
4 zeer veel
#3
In welke mate bent u blij een vouw te zijn?
$keuzen
1 geheel niet
2 een beetje
3 tamelijk veel
4 zeer veel
#4
is de route goed verlopen en kreeg u de juiste vraag?
$keuzen
1. Ja
2. Nee
##
In het derde veld staan de scoringssleutels
met de volgende subvelden :
- de schaalnaam
- voor elke vraag in die schaal het vraagnummer en op een nieuwe regel de weging van de antwoorden
- na de laatste vraag komt een "$" gevolgd door een van de woorden "deciel","stanine","t-score","T-score", "lintrans" of "mean-sd"
- voor elke normgroep:
- zes getallen die de kenmerken van een normgroep omschrijven:
- sexe: 1=man 2=vrouw
- leeftijd ondergrens
- leeftijd bovengrens
- opleiding ondergrens
- opleidingsbovengrens
- groepskenmerk:1,2,3,
- 10 decielgrenzen voor deze normgroep.
- na de laatste normgroep ##
$lintrans
0 0 0 0 0 0 normgroep algemeen
5*X+12 ++ lineaire transformatie geeft normscore++
$mean-sd
0 0 0 0 0 0 normgroep algemeen
100.0 7.35
Het eerste getal van de normregel bevat de begin(ruwe)score van de t-tabel.
volgende getallen bevatten de t-score van hoog naar laag voor alle ruwe scores
$Hier gelden de decielgrenzen ongeacht de kenmerken, die immers 0 zijn. Het eerste deciel loopt van 0 tot en met 4; het laatste geldt enkel de score 40.
0 0 0 0 0 0
4 8 12 16 20 24 28 32 40 40
#
$decielDe klassen die hier worden opgegeven gelden ongeacht de normkenmerken en de eerste klasse heet "zeer weinig" en loopt van de minimale testscore tot 2. Gevolgd door de klasse "weinig" die loopt van de score 3 tot en met 4. enz.
0 0 0 0 0 0 (normen voor iedereen)
1 2 3 4 5 6 7 8 9 10
$klassen
0 0 0 0 0 0 (normen voor iedereen in klassen)
zeer weinig|2|weinig|4|gemiddeld|7|veel|9|zeer veel|10
#
In het vierde veld staan de regels voor
rapportgenereren (zie 3.
Rapporten generen.)
De velden 1, 2, en 3 zijn verplicht. Indien het vierde veld ontbreekt
wordt er geen tekst gegenereerd.
In het vijfde veld staan de regels om
andere applicaties te starten (zie
CDLJavaApplicaties.)
De velden 1, 2, en 3 zijn nu niet verplicht. Indien het derde
en/of vierde veld ontbreekt, wordt er respectievelijk niet gescoord en
geen tekst gegenereerd.
In het zesde veld staan de regels voor
Formulieren (zie CDLJavaformulier.)
De velden 1, 2, 3 en 4 zijn nu niet verplicht. Indien het vierde veld
ontbreekt wordt er geen tekst gegenereerd.
Indien in een lijst de velden 1, 2 , 5 en 6 leeg zijn en veld 3 gevuld
is kan men de schaalscores van de schalen die in veld 3 genoemd worden,
invoeren via CDLJava. De schaalscores kunnen automatisch
gescoord worden en als veld 4 gevuld is wordt er ook tekst gegenereerd.
Zie voorbeeldlijst
factorscore.lijst
waarin de schaalscores van kwis1 en kwis2 ingevoerd kunnen worden; een
voorbeeld met tekstgeneratie.
Een ander voorbeeld is WT15.lijst
waarmee de testscores van de Vijftien Woorden Test die buiten CDLJava
afgenomen is, ingevoerd kunnen worden.
Het maken van een rapportgenerator vereist enige kennis van CDLJava,
de vragenlijst en het maken van tekstjes. Vooraf moet men beslissen bij
welke scoren hoort welke tekst. Deze teksten staan als kleine tekstbestanden
in de map "cdljava\lijsten.rap". Doorgaans zullen dit meerder teksten per
schaal zijn; zo bevat de rapportgenerator van de EQ dertien bestanden.
Zie: "cdljava\lijsten\rap".
CDLJava kent twee methoden voor tekstgeneratie: 1. Voor elke score-range
een tekst en 2. Tekst met variabelen. Deze methoden mogen ook gecombineerd
worden.
3.1 Voor elke scorerange een tekst
Voor elke scorerange van een schaal waarover men wil rapporteren moet men een tekst maken en deze bewaren in een tekstbestand met een unieke naam. Vervolgens maakt men de regels voor het rapportgenereren: deze staan in het lijstbestand in het vierde veld. Voor de EQ ziet dit er als volgt uit:
~De eerste regel bevat de naam van de rapportgenerator en wordt door CDLJava niet gelezen. Elke volgende regel bevat na een hekje (#) een schaalnaam met een acht getallen tussen "|" . De getallen hebben de volgende betekenis:eq rapportgenerator
#EQ-score |0|0|0|0|0|0| 0|1000 |eq_intro.rap |altijd intro
#EQ-score |0|0|0|0|0|0|31|1000|eq_hoog.rap|hoog voor allen
#EQ-score |0|0|0|0|0|0| 10| 30|eq_mid.rap|midden voor allen
#EQ-score |0|0|0|0|0|0| 0|9 |eq_laag.rap| voor allen laag
#Zelfkennis |0|0|0|0|0|0| 0|2 |eq_z_laag.rap| voor allen laag
#Zelfkennis |0|0|0|0|0|0| 6|1000|eq_z_hoog.rap| voor allen hoog
#Optimisme |0|0|0|0|0|0| 6|1000|eq_o_hoog.rap| voor allen hoog
#Optimisme |0|0|0|0|0|0| 0|2 |eq_o_laag.rap| voor allen laag
#Afzien |0|0|0|0|0|0| 6|1000|eq_a_hoog.rap| voor allen hoog
#Afzien |0|0|0|0|0|0| 0|2 |eq_a_laag.rap| voor allen laag
#Empathie |0|0|0|0|0|0| 6|1000|eq_e_hoog.rap| voor allen hoog
#Empathie |0|0|0|0|0|0| 0|2 |eq_e_laag.rap| voor allen laag
#Sociale_vaardigheden |0|0|0|0|0|0| 6|1000|eq_sv_hoog.rap| voor allen hoog
#Sociale_vaardigheden |0|0|0|0|0|0| 0|2 |eq_sv_laag.rap| voor allen laag
#EQ-score |0|0|0|0|0|0| 0|1000 |eq_tips.rap |altijd tips~
- sexe: 1=man 2=vrouw 0=niet van toepassing
- leeftijd ondergrens 0=niet van toepassing
- leeftijd bovengrens 0=niet van toepassing
- opleiding ondergrens 0=niet van toepassing
- opleidingsbovengrens 0=niet van toepassing
- groepskenmerk:1,2,3,. 0=niet van toepassing
Alle teksten van een rapportgenerator mogen in één
bestand worden ondergebracht. De teksten worden dan gescheiden door een
#. De eerste regel direct na het # kan gebruikt worden als een commentaarregel
en wordt niet getoond bij het rapport genereren. In het lijstbestand geeft
men direct na de bestandsnaam met een getal aan welk tekstdeel uit het
bestand gekozen moet worden.
Bv. voor kwis2 staan alle rapportteksten in bestand kwis2.rap
met de volgende regels in het rapportveld van het bestand kwis2.lijst.
kwis2 rapportgenerator
#kwis2-totaal |0|0|0|0|0|0| 0|1000|kwis2.rap 1|altijd intro
#kwis2-totaal |0|0|0|0|0|0| 0|0|kwis2.rap 2|score 0
#kwis2-totaal |0|0|0|0|0|0| 1|1|kwis2.rap 3|score 1
#kwis2-totaal |0|0|0|0|0|0| 2|2|kwis2.rap 4|score 2
#kwis2-totaal |0|0|0|0|0|0| 3|3|kwis2.rap 5|score 3
#kwis2-totaal |0|0|0|0|0|0| 4|4|kwis2.rap 6|score 4
#kwis2-totaal |0|0|0|0|0|0| 5|5|kwis2.rap 7|score 5
#kwis2-totaal |0|0|0|0|0|0| 6|6|kwis2.rap 8|score 6
#kwis2-totaal |0|0|0|0|0|0| 7|7|kwis2.rap 9|score 7
#kwis2-totaal |0|0|0|0|0|0| 8|8|kwis2.rap 10|score 8
#kwis2-totaal |0|0|0|0|0|0| 9|9|kwis2.rap 11|score 9
#kwis2-totaal |0|0|0|0|0|0| 10|10|kwis2.rap 12|score 10
Het tekstbetand kwis2.rap bevat alle teksten:
# 1 kwis 2 intro tekst
Kwis 2De uitslag van deze kwis is geen indicatie voor wat dan ook.
Toch is het leuk een goede score te halen of niet soms.....
kwis2 rapportgenerator
# 2 score 0
Helaas geen enkele vraag goed ..... dat geeft te denken.
Nog eens proberen dan maar.
# 3 score 1
Helaas maar een enkele vraag goed ..... dat geeft te denken,
hoewel het is een begin.
Nog eens proberen dan maar, eventueel hulp halen.
#4 score 2
Helaas maar twee vragen goed ..... niet veel,
dat moet met enig rondvragen beter kunnen.Nog eens proberen.
#5 score 3
Drie vragen goed ..... niet echt veel,
hoewel het is een begin.
Nog eens proberen dan maar, eventueel hulp halen.
#6 score 4
Vier vragen goed ..... dat wordt wel wat,
hoewel het kan beter.
Nog eens proberen dan maar, eventueel hulp halen.
#7 score 5
De helft goed, vijf van de 10 dus ..... ,
er is dus nog verbetering mogelijk.
Nog eens proberen dan maar?
#8 score 6
Een meer dan de helft goed, zes van de 10 dus ..... ,
is dat net voldoende?
Nog eens proberen dan maar?
#9 score 7
Twee meer dan de helft goed, zeven van de 10 dus ..... ,
is dat voldoende of kan het beter?
Nog eens proberen dan maar?
#10 score 8
Acht vragen goed, dat is een mooie score
is dat genoeg of kan het beter?
Nog eens proberen dan maar?
#11 score 9
Negen van de 10 vragen goed ..... , Mooie score!
Helaas kan ik niet zeggen welke fout is.
Daarvoor moet je elk antwoord apart analyseren en dat kan ik niet.....
#12 score 10
Een perfecte score alle 10 de vragen goed.
Geluk gehad of gewoon veel weten? In dat laatste geval
moet het vervelend zijn met u te Trivianten....
#
3.2 Tekst met variabelen
Het werken met een tekst met variabelen betekent dat in een tekst één of
meerdere variabelen worden opgenomen, die later door CDLJava ingevuld worden.
De regels voor het rapportgenereren bepalen wat er in een variabele komt.
Bij de vragenlijst mood is deze techniek toegepast. De vragenlijst mood
heeft maar één tekstbestand:
"mood.rap"
waarin de volgende tekst staat:
StemmingsmetingEen variabele staat tussen twee $-tekens. De eerste variabele $mood_ontstemming$ wordt later afhankelijk van de score op de schaal Totaalscore_ontstemming gevuld met één van de woorden "hoge" ,"gemiddelde" of "lage".De uitslag van deze stemmingsmeting begint met een globale beschrijving van uw stemming waarna
een detailbeschrijving volgt van de vijf onderdelen.
Uw stemming wordt steeds vergeleken met die van vele andere mensen die deze lijst eerder invulden.
Uw algemene stemming wijst op een $mood_ontstemming$ mate van ontstemming.U beschrijft u zelf op dit moment als $mood_depressie$ neerslachtig en $mood_gespannen$ gespannen.
U bent $mood_vermoeid$ vermoeid en voelt zich $mood_levendig$ levendig. Uw actuele woede is nu $mood_woede$.
~De eerste regel beschrijft dat ongeacht de kenmerken (zijn allemaal 0) de variabele $mood_ontstemming$ gevuld wordt met het woord "hoge" als de score van de schaal Totaalscore_ontstemming tussen 102 en 1000 ligt (de score 1000 wordt nooit bereikt). Ligt de score van deze schaal tussen 64 en 101 dan wordt de variabele gevuld met het woord "gemiddelde". Zo wordt voor elke scorerange de variabele $mood_ontstemming$ gevuld. Elke variabele wordt zo gevuld afhankelijk van kenmerken en scorerange. De laatste regel van dit voorbeeld zorgt ervoor dat het tekstbestand mood.rap altijd opgehaald wordt. CDLJava vult automatisch de variabelen in de tekst.mood rapportgenerator
#Totaalscore_ontstemming |0|0|0|0|0|0|102|1000|$mood_ontstemming=hoge$|hoog voor allen
#Totaalscore_ontstemming |0|0|0|0|0|0| 64| 101|$mood_ontstemming=gemiddelde$|midden voor allen
#Totaalscore_ontstemming |0|0|0|0|0|0| 0|63 |$mood_ontstemming=lage$| voor allen laag
#Depressie |0|0|0|0|0|0|27|1000|$mood_depressie=erg$|hoog voor allen
#Depressie |0|0|0|0|0|0| 14| 26|$mood_depressie=niet tot enigszins$|midden voor allen
#Depressie |0|0|0|0|0|0| 0|13 |$mood_depressie=geheel niet$| voor allen laag
#Woede |0|0|0|0|0|0|17|1000|$mood_woede=hoog$|hoog voor allen
#Woede |0|0|0|0|0|0| 9| 16|$mood_woede=gemiddeld$|midden voor allen
#Woede |0|0|0|0|0|0| 0|9 |$mood_woede=laag$| voor allen laag
#Vermoeidheid |0|0|0|0|0|0|20|1000|$mood_vermoeid=erg$|hoog voor allen
#Vermoeidheid |0|0|0|0|0|0| 10| 19|$mood_vermoeid=enigszins$|midden voor allen
#Vermoeidheid |0|0|0|0|0|0| 0|9 |$mood_vermoeid=niet$| voor allen laag
#Levendigheid |0|0|0|0|0|0|17|1000|$mood_levendig=erg$|hoog voor allen
#Levendigheid |0|0|0|0|0|0| 10| 16|$mood_levendig=enigszins$|midden voor allen
#Levendigheid |0|0|0|0|0|0| 0|9 |$mood_levendig=niet$| voor allen laag
#Gespannenheid |0|0|0|0|0|0|21|1000|$mood_gespannen=erg$|hoog voor allen
#Gespannenheid |0|0|0|0|0|0| 12| 20|$mood_gespannen=niet tot enigszins$|midden voor allen
#Gespannenheid |0|0|0|0|0|0| 0|11 |$mood_gespannen=niet$| voor allen laag
#Totaalscore_ontstemming |0|0|0|0|0|0| 0|1000 |mood.rap |altijd tekst
~
Voor een betere prestatie op het netwerk kunnen vragenlijsten worden ingepakt
in ZIP-bestanden. Geef het ZIP-bestand dezelfde naam als de lijst.
Er mag slechts één lijst in het ZIP-bestand staan.
Bijvoorbeeld: de vragenlijst npv.lijst wordt ingepakt in npv.zip.